On June 4, 2026, ChatGPT stopped asking what it should remember about you. Now it just reads everything you have ever told it and decides for itself. The feature is genuinely useful. The way it shipped is a masterclass in trading consent for convenience — and a teardown every product manager should study.
A ChatGPT user opened their memory settings one afternoon in June to see what the AI had saved about them. They expected a short list , the things they had explicitly asked it to remember. Instead, they found a profile. Their job, health worries and relationship details. Things they had mentioned once, in passing, months ago, never imagining the machine was keeping notes.
This was not a bug. This was the feature working exactly as designed. In a 2026 study presented at the ACM CHI Conference, researchers interviewed 20 ChatGPT users about exactly this moment ,and most of them reported the same reaction: surprise, and sometimes discomfort, at what the system had quietly remembered. The researchers gave it a clinical name: negative expectancy violation. In plain terms: the AI knew more than people thought, and finding out did not feel good.
On June 4, 2026, OpenAI rolled out Dreaming V3 , a new ChatGPT memory architecture that reads across years of your past conversations and synthesises a model of who you are, automatically, without a single instruction from you. The capability is real and useful. But this teardown is about a product decision underneath it: OpenAI changed what ChatGPT remembers, how it remembers, and how much you can see — and most users will never notice it happened.
💡 Core premise
ChatGPT memory’s Dreaming V3 is not a privacy scandal. It is a consent design failure. OpenAI shipped a genuinely better memory system while quietly removing the one thing that made the old system trustworthy: a list users could actually see and control. The capability went up. The auditability went down. That trade is the teardown.
What Actually Changed in ChatGPT Memory
To understand why Dreaming V3 unsettled people, you need to know what it replaced. The old system had a quality that the new one does not: every memory was traceable to something you said.
From a list you controlled to a profile that writes itself
Before June 4, ChatGPT memory worked on two layers. There was an explicit list of saved facts ,things you had stated or confirmed ,and Dreaming V0, a background process introduced in April 2025 that could reference broader chat history. The saved list was the backbone. It was, in effect, a contract: every entry traced back to something you had actually told it.

🔬 Technical Teardown — What Dreaming V3 Changed
Memory now writes itself
A single asynchronous background process now synthesises memory from many conversations at once. It automatically captures context that arises naturally in conversation and updates existing memories as your circumstances change. No “remember this” instruction required. The saved-memories list is no longer the backbone — the synthesis is.
It remembers what it inferred, not just what you said
This is the critical shift. The old list contained facts you confirmed. Dreaming V3 also remembers what it inferred about you ,and then quietly revised. OpenAI’s own example: a memory reading “you’re going to Singapore in July” rewrites itself to “you went to Singapore in July 2026” after the trip. Useful. Also: the system is now drawing conclusions you never explicitly approved.
The audit trail shrank
The new Memory Summary page adds correct, dismiss, and instruct controls. But OpenAI acknowledges the summary “may not include everything ChatGPT remembers.” With the old list, the list WAS the memory. Now the visible summary is a window onto a larger, synthesised state you cannot fully see. The granular, traceable audit trail is gone.
To be fair to OpenAI, the capability jump is real. Factual recall climbed from 41.5% under the old approach to 67.9% with the Dreaming background process. Users no longer have to nudge the AI with “remember I’m vegetarian” every session. For anyone who has re-explained their project to ChatGPT for the tenth time, this is a genuine improvement. The problem is not the capability. The problem is what was quietly removed to deliver it.
“With saved memories, the list was the contract. With dreaming, ChatGPT also remembers what it inferred and then quietly revised.”— Nerd Level Tech, June 2026
The ChatGPT Memory Numbers That Should Worry Product Teams
The discomfort is not anecdotal. The research and the regulatory response both point the same direction. Here is what the data says about the scale of the ChatGPT memory consent gap.
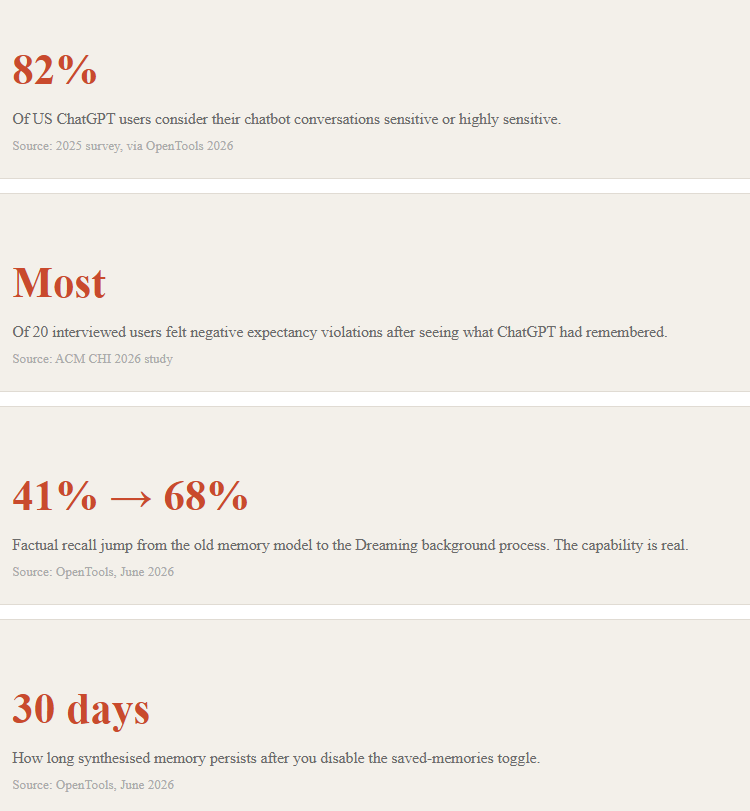
Read those numbers together. The vast majority of users treat their ChatGPT conversations as sensitive. The vast majority of studied users felt uncomfortable when they saw what was remembered. And the feature shipped with a summary page that, by OpenAI’s own admission, does not show everything. When 82% of your users consider the input sensitive, the bar for transparency on what you retain should be higher, not lower.
⚠️ The attack surface nobody discusses
Tenable Research demonstrated in November 2025 that because memories are appended to the system prompt, a maliciously crafted prompt injected via a third-party source could potentially update persistent memory — creating an exfiltration channel that survives across sessions. OpenAI has not disclosed whether Dreaming V3 closes this hole. A memory that writes itself automatically is also a memory an attacker may be able to write to.
The Root Cause of the ChatGPT Memory Trust Gap
The Dreaming V3 capability is excellent engineering. The trust gap comes from a product philosophy decision about who controls the memory , and the answer quietly shifted from the user to the system.
Consent moved from explicit to assumed
The old saved-memories list was built on explicit consent. You said “remember this,” or you confirmed something, and only then did it enter memory. Every entry was a decision you made. Dreaming V3 inverts that. The default is now that everything you say is potential memory material, synthesised automatically, unless you go and turn it off. Consent moved from opt-in to opt-out ,and most users do not know there is anything to opt out of.
The inference problem
There is a meaningful difference between a system remembering what you told it and a system remembering what it concluded about you. The first is recall. The second is profiling. When ChatGPT infers that you are anxious about your job, or going through a relationship change, or managing a health condition , based on the pattern of your conversations rather than an explicit statement ,it has built a psychological profile you never authorised and cannot fully inspect. The European Data Protection Board said exactly this on June 5, 2026: persistent AI memory constitutes profiling under GDPR, which triggers consent and right-to-erasure obligations. The regulator saw the same line the users felt.
The auditability collapse
The deepest root cause is the loss of a verifiable audit trail. With a discrete list, the list was the truth, you could read it, trust it, and act on it. With synthesised memory, the summary page is a representation of a larger hidden state, and OpenAI admits it is incomplete. You cannot fully verify what the system knows about you. For a feature operating on data 82% of users call sensitive, an unverifiable memory state is the core design flaw. Everything else flows from it.
Where OpenAI’s PM Team Got the ChatGPT Memory Rollout Wrong
The engineering is strong. The product management decisions around consent, transparency, and defaults are where the avoidable damage lives. Here are the three mistakes.
PM mistake 1: shipping a profiling system as a convenience update
Dreaming V3 was framed as a personalisation improvement – better continuity, fresher context, less repetition. But architecturally, it is a profiling system that infers and stores psychological context automatically. Framing a profiling change as a convenience feature means most users never engaged with the consent decision at all. As one analysis put it, most users likely will not even notice it happened. When a change of this depth ships invisibly, the absence of outcry is not consent. It is unawareness.
PM mistake 2: removing auditability while adding capability
The right version of this update keeps the capability and keeps the audit trail. OpenAI did not have to choose between a smart memory and a fully inspectable one — that was a product decision, not a technical necessity. By letting the visible summary become incomplete, OpenAI removed the one property that made the old system trustworthy. Capability went up; the user’s ability to verify went down. For a trust-critical feature, that is the wrong trade.
PM mistake 3: opt-out defaults on sensitive data
When 82% of users consider the underlying data sensitive, the correct default is opt-in, not opt-out. Dreaming V3 makes automatic synthesis the default and puts the burden on users to discover the controls and disable them. Worse, disabling the toggle still leaves synthesised memory live for 30 days. A privacy-respecting default would have made automatic inference something users switch on after understanding it — not something they must hunt down and switch off after being surprised by it.
“Persistent AI memory has moved from a convenience feature to a trust architecture decision.”— 1000.software analysis, June 2026
How OpenAI Should Have Shipped ChatGPT Memory
The capability deserved to ship. A more trustworthy version was fully available. Here is what would have preserved user trust while keeping the better memory.
01. Make automatic synthesis opt-in, with a clear first-run explanation
The first time Dreaming V3 activates, it should stop and explain plainly: “ChatGPT can now build a profile of you automatically from your past conversations, including things it infers. Do you want this on?” Let users choose with full understanding. An opt-in built on a clear explanation costs some adoption but buys enormous trust — and it is the difference between a feature users embrace and a feature users feel was done to them.
02. Keep the audit trail complete
The Memory Summary page must show everything the system uses, not a curated subset. If the synthesised state is too large to display in full, that is a signal the system is remembering more than a user can reasonably consent to — not a reason to hide it. A complete, inspectable memory is the single most important trust feature OpenAI could ship, and it abandoned it.
03. Separate “what you told me” from “what I inferred”
The memory view should clearly distinguish facts the user stated from conclusions the system drew. Inferences are the sensitive category — they are where profiling lives. Letting users see, correct, and delete inferences specifically would address the exact discomfort the CHI study documented. People are far more comfortable with a system that says “here is what I concluded, correct me” than one that quietly concludes and never shows its work.
04. Honour the disable toggle immediately
When a user turns memory off, synthesised memory should stop being used immediately, not persist for 30 days. A grace period on retention undermines the entire purpose of the control. If a user has decided they are uncomfortable, the product should respect that decision the moment it is made.
05. For teams and PMs: treat AI memory as a governance decision, not a UX toggle
If your organisation uses ChatGPT, Dreaming V3 means the assistant may now synthesise and retain context from your team’s conversations — including on free personal accounts that connect Gmail. Every team needs a documented policy on what may be entered into ChatGPT, which accounts are permitted, and how memory is managed. This is no longer a personal preference. It is an organisational data-governance question that landed on every PM’s desk on June 4.
The VulpisLab Verdict on ChatGPT Memory
🔍 VulpisLab Verdict
Severity: High. Nothing here is malicious, and the capability is a real improvement. But ChatGPT memory’s Dreaming V3 made a quiet trade that cuts against user trust: it increased what the system knows while decreasing what users can see and control. When the underlying data is something 82% of users call sensitive, that trade is the wrong one — and regulators have already noticed.
Most exposed: Privacy-conscious individuals who do not know the default changed, and organisations whose staff use personal ChatGPT accounts for work. The feature now synthesises profiles automatically, the summary page is admittedly incomplete, and free-tier accounts can connect Gmail. The user who opens their memory settings and feels that jolt of “how does it know that?” is not paranoid. They are responding correctly to a consent decision that was made for them.
The one lesson for PMs: Capability and consent are not the same axis, and improving one does not justify quietly weakening the other. You can ship a smarter memory and a fully auditable one at the same time — OpenAI chose not to. Before you ship any feature that infers and retains user data, ask the question this rollout skipped: would a user who fully understood this choose to turn it on? If the honest answer is uncertain, the default should be off.
The PM checklist before shipping any AI memory or personalisation feature
- Is automatic data retention opt-in, or are you relying on users not noticing?
- Can users see everything the system remembers, or only a curated summary?
- Do you distinguish what the user stated from what the system inferred?
- When a user disables the feature, does retention stop immediately?
- Have you tested the “how does it know that?” reaction before launch?
- Does your rollout treat memory as a trust decision, not just a UX improvement?
VulpisLab — AI product teardowns for PMs, engineers, and founders who build with and on top of AI. No hype. No vendor copy. Just teardown and verdict.
Read :- Issue #01: The Hallucination Tax ·
Issue #02: Microsoft Copilot Reliability ·
Issue #03: GitHub Copilot Billing.
Sources
Primary sources:
Tenable Research — original security advisory (memory exfiltration): tenable.com/security/research/tra-2025-11
Tenable Research — “HackedGPT” full report: tenable.com/blog/hackedgpt
ACM CHI 2026 study, “Relational Gains, Privacy Strains”: dl.acm.org/doi/full/10.1145/3772318.3791635
Reporting & analysis:
TechTimes (audit trail analysis): techtimes.com — Dreaming update
OpenTools (82% sensitive stat; 41→68% recall): opentools.ai — Dreaming V3
The Hacker News (Tenable coverage): thehackernews.com
Nerd Level Tech (“the list was the contract” framing): nerdleveltech.com
EDPB GDPR profiling ruling, via Windows News: windowsnews.ai
Digital Applied (free-tier Gmail personalization): digitalapplied.com