Microsoft Copilot suffered three major outages in 11 days in June 2026. No financially backed SLA. There is no offline fallback. No warning to users. This is not an infrastructure story. This is a product management failure — and every enterprise team building on AI needs to understand why.
Here is the number that matters: 614 minutes. That is how much downtime Microsoft 365 delivered in Q1 2026 — the worst quarterly uptime figure recorded since analysts began tracking it in 2013. And that was before June.
In the first 11 days of June 2026, Microsoft Copilot failed three times. June 1: a six-hour outage caused by a misconfigured load-balancing change. May 29: a load-shedding algorithm failure. June 11: a seven-hour global outage when a faulty deployment broke authentication with Microsoft Graph. Millions of enterprise users. Zero advance warning. No financially backed SLA covering Copilot specifically.
This teardown is not about whether cloud services go down. They do. This teardown is about the product management decisions that turned routine infrastructure incidents into a full enterprise reliability crisis — and what every PM building on AI infrastructure must learn from it.
💡 Core premise
Microsoft Copilot's reliability crisis is not an infrastructure failure. It is a product decision failure. Microsoft shipped Copilot from optional feature to mandatory infrastructure without shipping the reliability architecture that infrastructure demands. That gap is the teardown.
What Actually Happened: The Microsoft Copilot Reliability Timeline
To understand the Microsoft Copilot reliability crisis, you need the full timeline , not just the June 11 outage that made headlines.
The three failures in 11 days
🔬 Technical Teardown — June 2026 Outage Timeline
May 29, 2026 — Load-Shedding Failure
A misconfigured load-shedding algorithm began dropping user requests under peak load. Copilot became intermittently unresponsive across Microsoft 365 apps. Root cause: a configuration change deployed without sufficient traffic simulation at enterprise scale.
June 1, 2026 — Six-Hour Global Outage
A misconfigured load-balancing change caused app load failures and timeout errors worldwide. Users saw blank panes, spinning wheels, and generic error messages across web, mobile, and desktop. The disruption began at 8:00 AM UTC and lasted six hours. Word, Excel, Outlook, Teams — all affected simultaneously.
June 11, 2026 — Seven-Hour Authentication Collapse
A faulty software deployment broke authentication between Copilot and Microsoft Graph. A token exchange service began rejecting valid user credentials. Retry storms overloaded remaining healthy nodes. The fix required a full configuration rollback and traffic rerouting. Seven hours of global downtime. 9:00 AM UTC to 4:00 PM UTC — peak enterprise working hours.
The pattern is not bad luck. Three failures in 11 days, all caused by configuration changes deployed without adequate safeguards, all during peak enterprise hours, all with the same result: millions of workers staring at blank panes with no fallback and no clear timeline from Microsoft on restoration.
“Microsoft needs to treat Copilot like Exchange Online or Azure Active Directory. Those services have five-nines reliability baked into their DNA. Copilot isn’t there yet.”— Enterprise IT Leader, quoted in TechTimes, June 2026
The Microsoft Copilot Reliability Numbers Every PM Must Know
The individual outages are damaging. The aggregate picture is worse. Here is what the data says about the scale of the Microsoft Copilot reliability problem.
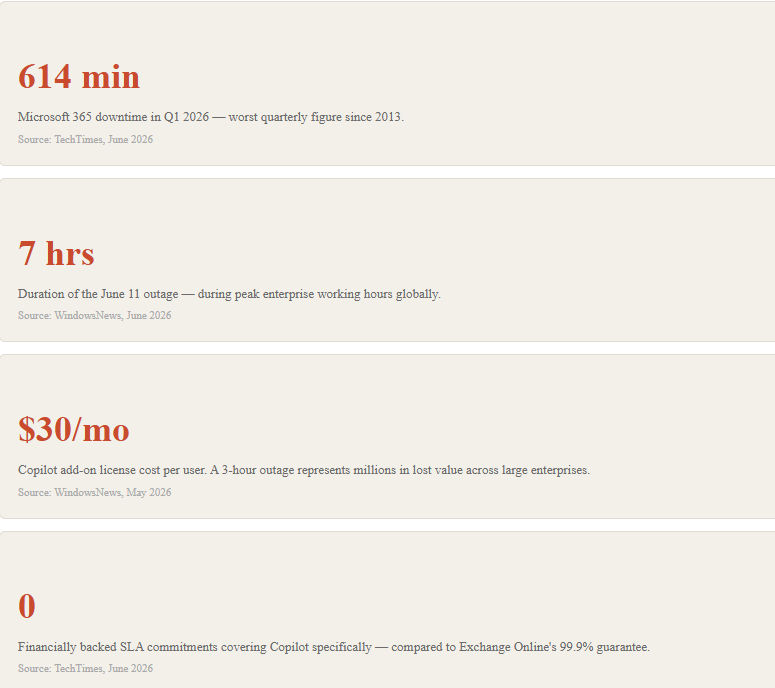
That last number is the most damaging. Exchange Online — Microsoft’s email service — carries a financially backed 99.9% uptime commitment. That means roughly 43 minutes of permitted downtime per month. Copilot carries no equivalent guarantee. Enterprise customers paying $30 per user per month for a tool woven into their daily workflows have no contractual protection when it fails. They discovered this during the outages.
⚠️ The silent failure problem
One legal-tech vendor’s document review tool — powered by the Copilot Graph API — stopped processing contracts during the June 11 outage without alerting end users. A backlog accumulated that took hours to clear after service resumed. When AI fails silently, the damage compounds invisibly.
The Root Cause of the Microsoft Copilot Reliability Crisis
Every individual outage had a technical root cause — a misconfigured load balancer, a faulty token exchange service, a bad deployment. However, those are symptoms. The actual root cause is a product architecture decision made 18 months ago.
The transition that was never managed
Microsoft spent 2024 and 2025 weaving Copilot into Word, Excel, PowerPoint, Outlook, Teams, Edge, Windows, and the broader Microsoft 365 estate. The product moved from optional novelty to daily workflow dependency at remarkable speed. What did not move at the same speed was the reliability architecture underneath it.
Exchange Online took years to reach five-nines reliability. SharePoint Online took years. Teams took years and a global pandemic forcing its adoption to accelerate that investment. Copilot was woven into all of those surfaces in under 18 months — without the equivalent reliability investment, the equivalent SLA commitment, or the equivalent fallback architecture.
The single point of failure design
The June 11 outage revealed a critical architectural problem. Copilot’s authentication runs through a centralised token exchange service connected to Microsoft Graph. When that single service began rejecting valid credentials, it did not degrade gracefully. It cascaded. Retry storms overloaded healthy nodes. The blast radius expanded from one service to every Copilot touchpoint across every Microsoft 365 app simultaneously.
Traditional Microsoft 365 outages map cleanly to one workload. An Exchange failure breaks email. A SharePoint failure breaks files. A Copilot failure — because it rides across all workloads — breaks everything it touches at once. The architectural blast radius of a Copilot failure is multiplied by every surface Microsoft has embedded it into.
The observability gap
When Outlook goes down, the symptom is obvious. When Copilot fails, users see a blank pane in Word, a timeout in Teams, a vague error in Excel. The path from symptom to cause is murky. Users report it as a browser issue, an Office issue, a license issue, or simply “AI being weird.” Enterprise IT desks receive fragmented, inconsistent reports. Microsoft’s own Service Health dashboard lumps all Copilot failures under a single “Copilot” category — making it impossible to distinguish between a Copilot Chat failure, a Copilot-in-app failure, and an underlying Azure OpenAI connectivity failure. That observability gap is a product decision, not an infrastructure constraint.
Where Microsoft’s PM Team Got the Copilot Reliability Story Wrong
The engineering failures are documented. The product management failures are more instructive — because they are the decisions that created the conditions for this crisis.
PM mistake 1: shipping infrastructure without infrastructure-grade reliability
There is a fundamental difference between a pilot and a dependency. A pilot can tolerate occasional weirdness. A production dependency needs service-level expectations, support paths, and graceful degradation. Microsoft marketed Copilot as a dependency — as the front end of modern work — while engineering it to pilot-grade reliability standards. That mismatch is a product management decision. Someone approved the roadmap. Another, set the reliability targets. Someone decided the SLA commitment could wait.
PM mistake 2: no offline mode, no fallback design
Traditional software outages are painful but manageable. Work can often continue offline. Copilot has no offline mode. When the cloud API is unavailable, the feature simply disappears. There is no degraded mode. There is no local fallback. Workers who rely on Copilot to draft content, analyse data, and manage communications are effectively unable to use those features at all during an outage. Microsoft has experimented with hybrid AI running on local NPUs, but the current Copilot experience is almost entirely cloud-bound. That is a product decision — and in June 2026, enterprise customers paid the cost of it.
PM mistake 3: no SLA before scale
Exchange Online reached 99.9% uptime before Microsoft made it the backbone of enterprise email infrastructure. Copilot became the backbone of enterprise productivity workflows before it reached any equivalent reliability standard — and without any equivalent contractual commitment. One CIO of a Fortune 500 financial firm told Windows News that his company delayed broader Copilot deployment specifically because of reliability fears. The customers who did not delay are now managing the consequences.
“We assumed Microsoft’s 99.9% SLA covered Copilot, but we forgot to ask: continuity for what?”— CTO, enterprise customer, quoted in WindowsNews, June 2026
How to Fix the Microsoft Copilot Reliability Problem: What Must Change
The reliability crisis is real. However, the mitigation is not complicated. It requires product discipline, not technical invention. Here is what Microsoft must do — and what enterprise teams must do independently.
01. Microsoft must issue a standalone Copilot SLA
Exchange Online has a financially backed 99.9% uptime commitment. Copilot must have the same. Without a contractual commitment tied to financial penalties, there is no forcing function on Microsoft’s engineering teams to prioritise reliability over feature velocity. Enterprise customers paying $30 per user per month for a workflow-critical tool deserve the same contractual protection they receive for email.
02. Microsoft must redesign for graceful degradation
When Copilot is unavailable, the user experience today is a blank pane and a generic error message. The correct design is a degraded mode — local model fallback for basic tasks, clear messaging about what is unavailable and why, and a restoration timeline communicated proactively through the Service Health dashboard rather than reactively after user reports spike on Downdetector.
03. Microsoft must fix the observability gap
The Service Health dashboard must distinguish between Copilot Chat, Copilot in individual apps, and underlying Azure OpenAI connectivity. Today all failures are lumped together. Enterprise IT administrators cannot triage effectively or communicate accurately to their organisations when the only status update is “Copilot — investigating.” Granular observability is table stakes for infrastructure-grade services.
04. Enterprise teams must build AI continuity plans now
Waiting for Microsoft to fix this is not a strategy. Enterprise teams must build their own resilience. That means documented degraded-mode procedures for every critical workflow that touches Copilot, multi-vendor AI strategies that maintain licences for alternative providers, and regular simulations of AI service failure — exactly as teams simulate Exchange failover and SharePoint restore today.
05. Procurement teams must negotiate AI-specific SLAs
Every enterprise renewing or expanding Copilot licences must negotiate AI-specific uptime commitments with financial penalties tied to violation. The standard Microsoft 365 SLA does not cover Copilot adequately. That is a contractual gap that procurement teams can close before the next outage — not after it.
The VulpisLab Verdict on Microsoft Copilot Reliability
🔍 VulpisLab Verdict
Severity: Critical. Three outages in 11 days during peak enterprise hours. Worst quarterly uptime since 2013. Zero financially backed SLA. This is not a run of bad luck — it is the predictable consequence of shipping a feature to infrastructure scale without infrastructure-grade reliability engineering.
Most exposed: Enterprise teams that have embedded Copilot into mission-critical workflows — legal document review, financial analysis, customer communications — without a fallback plan. The legal-tech vendor whose contract review tool silently stopped processing during the June 11 outage is not an edge case. It is the default outcome for any team that treats an AI feature as infrastructure without verifying it meets infrastructure-grade reliability standards.
The one action: Before your team expands Copilot usage into any critical workflow, document the degraded-mode procedure — what happens when Copilot is unavailable, who is responsible for switching to the fallback, and how long the fallback can sustain operations. That document does not exist in most enterprises today. It needs to exist before the next outage — not after.
The PM checklist before embedding any AI tool into critical workflows
- Does the vendor provide a financially backed SLA for this specific AI feature?
- What is the documented fallback when the AI service is unavailable?
- Does the AI fail silently or does it alert users and administrators immediately?
- Is the blast radius of an AI outage scoped — or does one failure cascade across all surfaces?
- Has the team simulated an AI service failure and tested the recovery procedure?
- Is there a multi-vendor strategy if the primary AI provider is unavailable?
VulpisLab — AI product teardowns for PMs, engineers, and founders who build with and on top of AI. No hype. No vendor copy. Just teardown and verdict. Read Issue #01: The Hallucination Tax.
Pingback: Inside the Github Copilot Billing And Trust Crisis - vulpislab.com
Pingback: The ChatGPT Memory Update: Trading User Consent for Convenience? - vulpislab.com