AI hallucination in production has moved from a research footnote to a $67 billion annual business liability. This teardown covers why it happens at the architectural level, what it costs by domain, and the mitigation stack that separates serious deployments from expensive experiments.
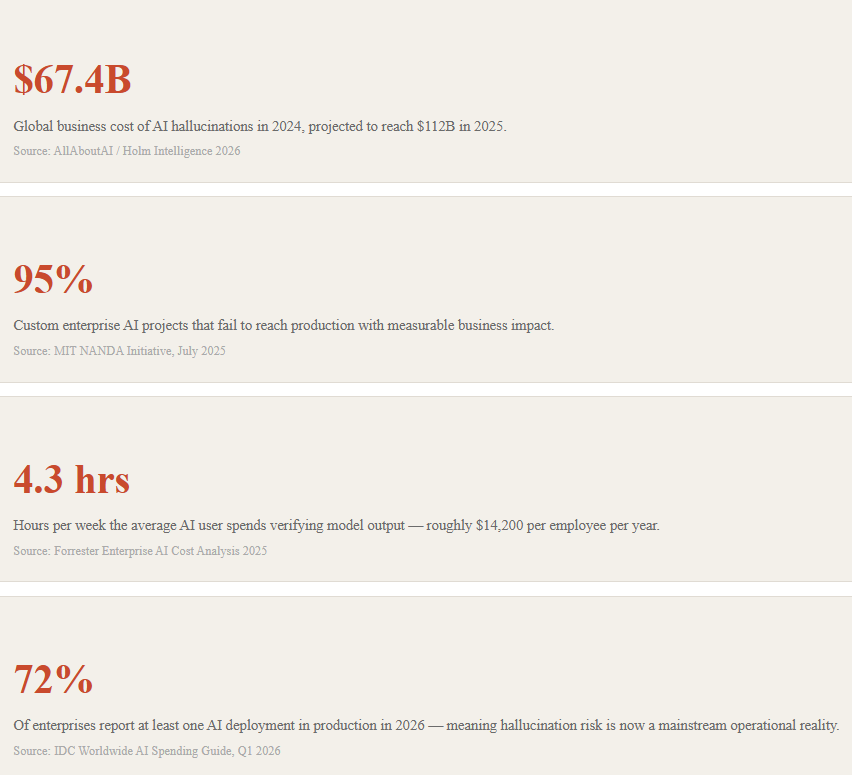
Here is a number that should make every product leader uncomfortable: $67.4 billion. That is the estimated global cost of AI hallucination in production in 2024 alone. It is projected to hit $112 billion in 2025. This damage does not come from bad actors or novel exploits. It comes from the AI products your team shipped this year, confidently making things up.
Hallucination describes what happens when a large language model generates output that is fluent, plausible, and completely wrong. A fabricated legal citation. A made-up drug dosage. A product specification that does not match the actual product. The model is not lying, it does not know the difference. That is precisely the problem.
This post is a product teardown. We will cover why AI hallucination in production happens at the architectural level, map the real-world damage domain by domain, and walk through what a production-grade mitigation stack actually looks like. The most dangerous myth in AI product management today is the belief that this is a model problem someone else will fix.
💡 Core premise
AI hallucination is not a bug in your model. It is an emergent property of how every large language model is fundamentally trained. You cannot prompt your way out of it. You can only engineer around it — or pay the tax.
The Root Cause of AI Hallucination in Production: It Is the Architecture
Most product teams treat hallucination as a quality issue , something to fix with better prompts or a more expensive model. This framing is wrong. Understanding why it is wrong changes how you build.
Every large language model trains on one fundamental objective: predict the next token. The model learns statistical patterns across billions of documents. It then produces the token sequence most likely to follow what came before. The model never learned what is true. It learned what is plausible. Those are radically different targets.
A 2025 mathematical proof , not a benchmark, a formal proof — confirmed that hallucinations cannot be fully eliminated under current LLM architectures. The auto-regressive nature of transformers prioritises generating plausible token sequences over ensuring factual accuracy. The model’s confidence and the model’s correctness are not the same signal. They were never the same signal.
“LLMs hallucinate because they were optimised for exactly one thing: predict the next token. They never learned the difference between truth and plausibility. They never learned when to abstain.”— Charan Panthangi, Medium, April 2026
Research from OpenAI’s September 2025 paper adds another layer. Models are actively trained to guess rather than abstain. Common benchmarks and instruction-tuning datasets reward confident answers over calibrated uncertainty. As a result, models learn to bluff. An MIT study from January 2025 quantified this: models use 34% more confident language when generating incorrect information. The wrong answers sound more certain than the right ones.
The four mechanical causes of hallucination
🔬 Technical teardown — hallucination root causes
1. Training data contamination
Web-scale corpora contain outdated, contradictory, and simply false information. The model memorises human falsehoods at scale. Temporal decay compounds the problem — a model trained through mid-2024 genuinely does not know what happened after that date. Rather than admit ignorance, it invents plausible-sounding answers.
2. Completion bias and error cascade
Each token is predicted based on the previously generated sequence. Small errors in early tokens do not stay small — they cascade. In multi-step reasoning chains, a single wrong premise at step 2 can produce a completely fabricated conclusion by step 8. This is why agentic systems that chain multiple LLM calls carry disproportionate risk.
3. Evaluation misalignment
Standard benchmarks reward confident fabrication over calibrated uncertainty. When “I don’t know” scores lower than a confident wrong answer, the model learns never to say it. Consequently, the training signal is broken upstream of the model release — before any product team touches it.
4. The creativity–factuality trade-off
The same mechanism that makes LLMs remarkably creative , probabilistic sampling from a broad distribution — is exactly what makes them hallucinate. Turn up creativity, and you turn up the hallucination rate. This is not a dial you can tune away. It is baked into the generative architecture itself.
The Real Cost of AI Hallucination in Production: Domain by Domain
Across multiple 2026 benchmarks, hallucination rates for commercial LLMs range from 15% to 52% depending on model and task type. However, aggregate rates hide the real story. Domain context is everything. The gap between a 1.5% rate on a grounded summarisation task and a 69–88% rate on a legal query is the difference between a useful product and a legal liability.
Key statistics every PM should know
Hallucination rates by domain
Legal queries: 69–88% hallucination rate
AI hallucination in legal contexts produces fabricated case citations, triggers court sanctions, and creates firm-level liability. Over 200 US courts now require explicit AI disclosure on legal filings. Stanford HAI research documented hallucination rates of 69–88% on high-stakes legal queries.
Medical case summaries: 43–64% hallucination rate
ECRI named AI chatbot misuse the number one healthcare technology hazard in 2026. In medical case summaries, hallucinations reached 64.1% without mitigation prompts. Incorrect dosages and diagnoses are not hypothetical risks — they are documented production failures.
Code generation (package names) : 5–22% hallucination rate
LLMs hallucinate npm and PyPI package names in 5–22% of suggestions. Attackers now register those non-existent packages in a supply-chain technique called “slop-squatting.” What starts as a hallucination becomes a security incident in production.
Customer support bots ; 15–27% hallucination rate
AI-powered customer support bots produce hallucinated responses in 15–27% of live interactions. Wrong return policies, fabricated delivery dates, and incorrect compatibility data are the most common failure modes. In 2024, 39% of AI support bots were pulled or significantly reworked because of hallucination errors.
Product descriptions and e-commerce : ~60% hallucination rate
A 2026 UC San Diego study found that AI-generated product summaries hallucinated in approximately 60% of cases — and those inaccurate summaries measurably influenced purchase decisions. When AI generates product descriptions, any fabricated detail becomes a promise to the customer, and a broken promise when the product does not match.
Grounded summarisation with RAG : 0.7–1.5% hallucination rate
This rate is acceptable for most enterprise use cases and is the clearest evidence of what proper architecture can achieve. When LLM output is grounded in retrieved, verified documents, the hallucination problem becomes manageable. The contrast with ungrounded generation is stark.
⚠️ The counterintuitive finding
Newer reasoning models like o3 and o4-mini can show higher hallucination rates on factual benchmarks than earlier models — because they make more claims overall. OpenAI’s explanation: a longer, more “reasoned” answer is not automatically a more reliable one. Do not mistake verbosity for accuracy.
Where Product Teams Make AI Hallucination in Production Worse
The data above describes a technology risk. However, the real failure is a product management failure. Commonly, teams make three systematic mistakes that turn a manageable technical risk into a production disaster.
Mistake 1: treating the model as the product
When a team builds an AI feature by pointing an LLM at a task with a prompt, they have not built a product. They have built a demo. Real products include error handling, fallback states, confidence thresholds, and output validation. None of those exist in a “model plus prompt” architecture.
As a result, the model’s confidence score and the user’s trust in the UI become indistinguishable. When the model is wrong at the 20% rate that is currently industry average, that trust erodes permanently and quickly.
Mistake 2: testing on clean data, then shipping to chaos
Enterprise AI teams benchmark on curated datasets. In contrast, users ask ambiguous, poorly scoped, contradictory questions in production. They ask them in languages, dialects, and domain jargons the model was never tuned for. The gap between demo performance and production performance is where 95% of AI projects fail, according to MIT’s NANDA research.
Furthermore, hallucination rates reliably increase with larger, messier inputs and more complex, multi-step queries — exactly the conditions of real-world production use.
Mistake 3: leaving the verification tax out of the business case
Forrester found the average employee spends 4.3 hours per week verifying AI output. That works out to roughly $14,200 per person per year. For a 500-person firm, that is $7.1 million annually spent checking the AI’s homework. This cost is almost never in the business case. It is always in the actual numbers.
“Enterprises are treating AI like software. It isn’t. Deploying AI is closer to the shift from steam to electricity than rolling out a new CRM. It demands reconfigured workflows, rebuilt data foundations, and new governance.”— Holm Intelligence Partners, May 2026
How to Reduce AI Hallucination in Production: The Mitigation Stack
There is no single fix for AI hallucination in production. The root cause is architectural and cannot be eliminated. What works is a layered defence that reduces the surface area and cost of each failure. The goal is to make the system fail gracefully, not make it perfect.
01. Retrieval-augmented generation (RAG) — the biggest lever
Grounding LLM output in retrieved, authoritative documents is the single most impactful intervention available today. OpenAI evals show hallucination rates drop below 2% on retrieval-grounded tasks, compared to 15–52% on open-domain generation. RAG turns the model from a knowledge store ,which it is poor at — into a reasoning engine over verified sources — which it excels at.
Every production AI product that handles factual claims should have RAG. Not as an enhancement. As a foundation.
02. Structured prompt engineering with mitigation prompts
A 2025 Nature study confirmed that prompt-based mitigation reduces hallucinations by approximately 22 percentage points. In medical AI specifically, structured prompts achieved a 33% reduction. Practical tactics include giving the model explicit permission to say “I don’t know,” enforcing chain-of-thought reasoning via output format, and adding self-consistency checks that ask the model to verify its own claims against the provided context.
These techniques are cheap to implement and carry measurable return on investment.
03. Multi-model verification and cross-checking
A June 2026 benchmark from Suprmind found that between one in three and one in two confidently stated answers had a substantive issue caught by a peer model. Running the same query through two models and surfacing their disagreement as uncertainty is a structurally sound defence for high-stakes decisions.
This approach is not about picking a winner between models. It is about surfacing where confidence in the UI should be lower than it currently is.
04. Output validation layers and confidence thresholds
Model output is not a final product — it is a draft that must pass through validation before reaching users. This validation includes schema checking for structured outputs, factual claim extraction and verification against ground-truth sources, and confidence calibration that surfaces uncertainty in the UI rather than hiding it.
The UX of uncertainty is a product decision. Designing it deliberately — with “I’m not sure, but…” language or a visible sources panel — is honest. A clean, confident answer with no caveats is not.
05. Human-in-the-loop review for high-stakes outputs
In legal, medical, financial, and compliance contexts, the human review step is not a weakness in the workflow. It is a safety-critical feature. Teams that remove human review to increase throughput are not optimising. They are transferring liability.
The key PM decision is identifying which outputs require human review — high stakes, novel queries, low-confidence signals — and which are safe to auto-publish — low stakes, high-confidence, grounded in RAG.
06. Production observability and hallucination monitoring
You cannot fix what you cannot measure. Production AI without observability is blind. Effective monitoring includes span-level tracing for multi-step reasoning chains, faithfulness scoring on sampled production traffic, and user correction tracking. When users edit or reject AI output, that is a hallucination signal — and most teams ignore it completely.
The LangChain State of Agent Engineering 2026 found that 89% of agent teams have now deployed observability. This is table stakes, not optional.
The PM Verdict on AI Hallucination in Production
🔍 Product teardown verdict
Hallucination is a product risk, not a research problem. Model providers are working on it, and some benchmarks are improving. However, a 2025 mathematical proof confirmed that hallucination cannot be fully eliminated at the architectural level. Product teams therefore own the mitigation layer — and most are not treating it with the engineering discipline it requires.
Three things separate AI products from expensive demos: RAG grounding that turns the model into a reasoner rather than a knowledge store; output validation that treats model responses as drafts rather than answers; and UI design that communicates uncertainty honestly instead of manufacturing false confidence.
The single most dangerous PM behaviour in 2026 is shipping AI into a domain with real-world consequences — legal, medical, financial, customer-facing — without a hallucination mitigation layer, and then calling it a “model limitation” when something goes wrong. That is not a model limitation. That is a product decision that was never made.
The PM checklist before shipping any AI feature
- Is there a RAG layer grounding outputs in verified sources?
- Does the UI communicate uncertainty, not just confidence?
- Is there output validation before user-facing rendering?
- Is human review in the loop for high-stakes outputs?
- Is hallucination monitoring live in production?
- Is the verification cost included in the business case?
Pingback: The Real Reason Microsoft Copilot Keeps Going Down - vulpislab.com
Pingback: Inside the Github Copilot Billing And Trust Crisis - vulpislab.com
Pingback: The ChatGPT Memory Update: Trading User Consent for Convenience? - vulpislab.com