The first time the team saw the new AI model working, the room was full of quiet confidence.
For weeks, engineers had been testing it against the old version. The model answered complex questions with more depth. It handled reasoning better. It gave cleaner citations. It seemed more useful, more fluent, and more intelligent. On internal dashboards, the numbers also looked promising, and for a moment, it felt like the hard part was already over.
Then the Technical Product Manager looked at the screen and asked a question that changed the mood of the room.
“What happens when real users start using it?”
Nobody answered immediately.
That silence mattered because everyone in the room understood something that does not always show up in model evaluation reports. A model can perform beautifully in controlled testing and still behave unpredictably when millions of real people start using it in the real world.
Real users do not behave like benchmark datasets. They ask half-formed questions while travelling in a cab. They mix English with other language like Hindi, Spanish etc. They type fast, leave context missing, ask sensitive questions, compare products, look for medical guidance, research financial decisions, and expect the system to respond quickly and correctly. More importantly, when an AI system answers confidently, many users assume the product knows what it is saying.
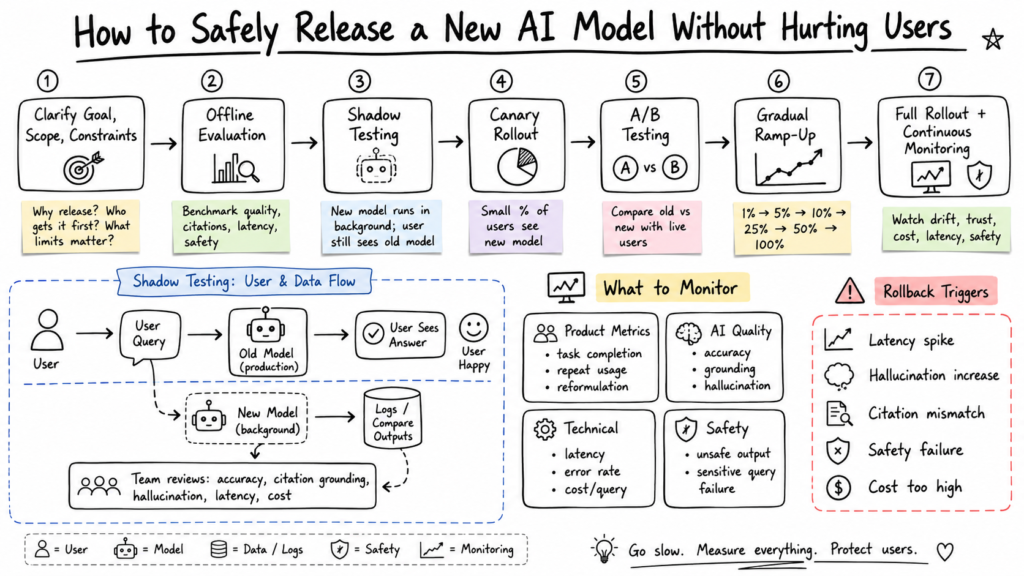
That is why teams must safely release a new AI model instead of treating it like a normal software deployment. In traditional software, a bug may break a button or slow down a page. In an AI product, a bad response can break trust. And once users stop trusting an AI product, the company has to work much harder to bring them back.
The Moment Before Launch
Imagine you are the Technical Product Manager for an AI search product similar to Google AI Mode.
The product helps users ask complex questions and get AI-generated answers with sources, reasoning, and follow-up support. Users may ask something simple like, “What is shadow testing?” or something more complex like, “Which health insurance plan is better for a family with elderly parents and diabetes history?” Both questions look like search queries, but the risk behind them is not the same.
Now your team has built a new model version. It is better at reasoning, better at summarizing, and better at giving structured answers. In internal testing, it performs well across many query types. The leadership team is excited because the new model can improve user experience, increase trust, and make the product feel more useful.
However, as the launch gets closer, the risks also become clearer. The new model may take longer to respond because it reasons more deeply. It may cost more per query because it uses more compute. It may perform very well in English but struggle with mixed-language queries. It may answer research questions beautifully but give too much confidence on sensitive topics. It may also reduce clicks to original sources because the AI answer becomes too complete.
This is where the release stops being a pure engineering decision and becomes a product decision.
If the team delays the launch, users may miss a better experience. However, if the team releases too quickly, users may face wrong answers, weak citations, slow responses, or unsafe suggestions. A Technical Product Manager has to stand between these two risks and design a rollout path that allows learning without harming users.
That is the real meaning of safe AI rollout.
The First Question Is Not “How Do We Launch?”
Many teams make the mistake of starting with the launch mechanism.
Someone says, “Let’s A/B test it.” Another person suggests, “Let’s release it to 10 percent of users.” A third person says, “Let’s start with one geography.” These ideas may be useful later, but they are not the right starting point.
Before deciding how to launch, the team must understand why the model is being launched.
A new AI model may be released for different reasons. Sometimes the goal is to improve factual accuracy. Sometimes the team wants better reasoning for complex queries. In other situations, the business may want lower latency, reduced infrastructure cost, stronger safety, better personalization, multilingual support, or improved citation grounding.
Each goal changes the rollout strategy.
For example, if the new model is being released to improve factual accuracy, then the team must focus on grounded answers, citation quality, unsupported claims, and hallucination rate. On the other hand, if the goal is to reduce latency, then the rollout must focus more on response time, timeout rate, infrastructure load, and cost per query. Similarly, if the goal is better personalization, the team must check whether the model improves relevance without creating privacy concerns or biased recommendations.
Therefore, the Technical Product Manager should begin by clarifying three things: the goal, the scope, and the constraints.
The goal explains why the model is being released. The scope explains who or what will receive the model first. The constraints explain what limits the team must respect while rolling it out.
These three questions keep the team from jumping into solutions too early.
Clarifying Scope With a Real Example
Let’s say the business goal is to improve answer quality for complex search queries. That sounds clear, but it is still not enough.
The next question is scope.
Will this model be used for all users from day one, or only a small percentage of traffic? Will it be launched globally, or only in one market? Will it support all languages, or only English first? Will it answer all query types, or will sensitive topics like health, finance, politics, and legal questions stay on the old model until safety checks are stronger?
This matters because not all user queries carry the same level of risk.
A query like “best noise-cancelling headphones under ₹10,000” is very different from “should I stop taking this medicine?” A product comparison query can tolerate some imperfection, but a medical or financial query needs much stricter guardrails. Similarly, a travel planning query may require freshness, while a coding query may require correctness and reproducibility.
Because of this, a safe rollout should not treat all traffic equally. The team can begin with lower-risk query categories, observe the model’s behavior, and then slowly expand into more sensitive areas only when the evidence supports it.
That is how good rollout design protects users without blocking innovation.
Constraints Are Not Excuses. They Are Guardrails.
Once the goal and scope are clear, the team must look at constraints.
This is where product reality becomes important.
A new model may be smarter, but can it respond within the existing latency limit? Can the infrastructure handle the additional load if traffic increases? Can the business afford the higher cost per query? Can the safety thresholds remain the same? Can the team roll back quickly if something goes wrong? Are there any compliance requirements that prevent certain query types from being served by the new model?
These questions may sound operational, but they are deeply product-related.
A user does not care that the new model has better reasoning if the answer arrives too late. A business cannot scale a model if every query becomes too expensive. A company cannot defend a launch if the model performs well on average but fails on sensitive topics.
That is why a strong Technical Product Manager does not only ask, “Can we launch this model?” They ask, “Can we launch this model safely, responsibly, and reversibly?”
That one word, reversibly, is very important. In AI rollout, the team should always have a way back.
Why A/B Testing Is Not Always the First Step
A/B testing is a powerful product tool, but in AI model rollout, it should not be the first live exposure step.
In A/B testing, real users see the new version. If the model gives a wrong answer, the user sees it. If the citation is weak, the user may still trust it. If the response is slow, the user feels the delay. If the answer is unsafe, the damage has already happened.
For normal product changes, such as changing a button color or rearranging a dashboard, this may be acceptable. However, AI systems behave differently because they can produce polished, confident answers even when they are wrong. That confidence makes the risk higher.
Before exposing users to the new model, the team needs a safer middle step.
That step is shadow testing.
Shadow Testing Is Like a Dress Rehearsal
Think of shadow testing like a dress rehearsal before a theatre performance.
The actors perform on the real stage. The lights are on. The sound system is tested. The team sees how everything works in the actual environment. However, the audience is not yet watching, so mistakes can be found without damaging the real show.
Shadow testing works in a similar way.
The new model runs in the background while users continue to see the old stable model. When a user asks a question, the old model gives the live answer. At the same time, the new model also processes the same query silently. The user never sees the new model’s response, but the system logs it internally so the team can compare both outputs later.
This gives the team something very valuable: real traffic without real user exposure.
Offline testing shows how the model behaves in a controlled environment. Shadow testing shows how the model behaves in the wild, where users are messy, unpredictable, and far more creative than test datasets.
For a Technical Product Manager, this is one of the most useful stages in safe AI rollout because it allows the team to learn before putting trust at risk.
A Simple Real-World Example
Imagine a user asks an AI search product, “What are the risks of investing in AI stocks right now?”
The current model gives the answer the user actually sees. Meanwhile, the new model also generates its own answer in the background. The user does not know this is happening, and their experience is not affected.
Later, the team compares both responses.
The product team checks whether the new model explained risk clearly. The AI team checks whether it made unsupported claims. The safety team checks whether it avoided giving direct financial advice. The engineering team checks whether it responded within the latency limit. The business team checks whether the answer still encouraged users to open reliable sources instead of blindly trusting the AI summary.
This is where shadow testing becomes powerful. It does not just answer the question, “Is the model better?” It helps the team ask a deeper question: “Is the model better in the actual product context?”
That difference matters.
The New Model Must Be Compared Like a Product
After shadow testing starts, the team should avoid one broad and lazy question: “Is the new model better?”
A better question is: “Better for whom, on which task, at what cost, and with what risk?”
This matters because model improvement is rarely equal across all situations. The new model may be better for long research queries but weaker for short factual searches. It may perform well for English users but struggle when users mix English and Hindi. It may reduce hallucination but increase latency. It may produce more complete answers but reduce source click-through because users stop visiting original websites.
For this reason, the team should compare the model across meaningful segments.
They can compare by query type, language, device, geography, user type, query length, and risk category. They can also separate commercial queries from informational queries because both affect the business differently. For example, a shopping-related query may affect revenue, while a health-related query may affect safety and trust.
This is where Technical Product Management becomes more than delivery management. The Technical PM is not only asking whether the model is smart. They are asking whether the model improves the product safely.
The Rollout Dashboard Should Tell the Whole Story
A safe AI rollout needs a balanced dashboard. Accuracy is important, but it is not enough.
The team needs product metrics, AI quality metrics, technical metrics, and safety metrics. These four groups together tell the real rollout story.
Product metrics show whether users are getting value. These include task completion rate, user satisfaction, repeat usage, follow-up rate, source click-through rate, and query reformulation rate. Query reformulation is especially useful because if users ask the same question again in a different way, it may mean the first answer did not help.
AI quality metrics show whether the model output is useful and reliable. These include answer accuracy, citation grounding, hallucination rate, unsupported claim rate, relevance score, retrieval quality, and human evaluation score. For AI search, citation grounding is critical because the answer should not only sound correct; it should be supported by reliable sources.
Technical metrics show whether the system can handle the new model. These include latency, timeout rate, error rate, cost per query, infrastructure load, model availability, and fallback rate. This matters because a better answer is not useful if the user leaves before receiving it.
Safety metrics protect users from harm. These include unsafe answer rate, sensitive query failure rate, policy violation rate, toxic output rate, bias complaints, and human escalation rate. For medical, legal, financial, political, or safety-related queries, these thresholds should be strict.
If safety fails, the rollout should pause, even if every other metric looks good.
No model upgrade is worth losing user trust.
Moving From Shadow Testing to Canary Rollout
If shadow testing looks healthy, the team can move to canary rollout.
This is the first time real users will actually see the new model, so the rollout should begin with a very small percentage of traffic. For example, the team may start with 1 percent of users or 1 percent of low-risk queries.
At this stage, the team watches the system closely. They check whether users are satisfied, whether latency remains stable, whether citations are correct, whether users ask fewer repeat questions, whether error rates stay normal, and whether safety issues remain under control.
If the metrics look healthy, the team can gradually increase traffic.
The rollout may move from 1 percent to 5 percent, then 10 percent, then 25 percent, then 50 percent, and eventually 100 percent. However, each step should depend on evidence, not excitement, pressure, or leadership impatience.
A safe rollout is not slow because the team lacks confidence. It is careful because the team understands the cost of breaking trust.
A/B Testing Comes After the Model Looks Safe
Once the model has passed shadow testing and canary rollout, A/B testing becomes useful.
Now the team can compare the old model and the new model with live users in controlled groups. This helps answer a deeper product question: “Is the new model actually better for users and the business?”
The team can check whether the new model improves task completion, reduces query reformulation, increases satisfaction, improves repeat usage, or improves source click-through. At the same time, they must watch whether latency increases, cost rises too much, safety issues appear, or certain user segments perform worse.
This matters because a model can look better in offline evaluation and still fail inside the real product. The real test is not whether the model is impressive in a demo. The real test is whether the overall product experience becomes better for users.
That is why the rollout sequence matters.
Offline evaluation comes first. Shadow testing comes next. Canary rollout follows. Then A/B testing proves product impact. After that, the team can gradually ramp traffic while continuing to monitor risk.
The Rollback Plan Should Exist Before the Fire Starts
Every safe rollout needs a way back.
A rollback plan should not be written after something breaks. It should be ready before the first user sees the new model.
The team should define clear rollback triggers. For example, they should pause or roll back if latency crosses the agreed limit, hallucination increases, citation mismatch rises, sensitive query failures increase, user satisfaction drops, error rate spikes, or cost per query becomes too high.
This protects the team from emotional decision-making.
During a launch, people often want to continue because they have invested time, effort, and reputation into the release. They may say, “Let’s wait one more day,” or “Maybe the metric will recover.” However, predefined rollback triggers create discipline. They make the decision data-driven instead of emotional.
A Technical Product Manager should make sure every rollout has a pause plan, a rollback plan, and an escalation path.
That is not pessimism.
That is responsible product leadership.
The Launch Does Not End at 100 Percent
Many teams think the rollout ends when the new model reaches 100 percent traffic.
It does not.
AI products are living systems. User behavior changes. News changes. Language changes. Product data changes. Regulations change. Competitors change. New edge cases appear. As a result, the model that works well today may drift tomorrow.
Because of this, post-launch monitoring is not optional.
The team must continue watching model drift, feedback trends, latency, safety failures, retrieval quality, citation quality, user complaints, cost trends, and new query patterns. This continuous monitoring helps the team catch issues before they become trust problems.
In AI products, launch is not the end of the story.
It is the beginning of continuous learning.
What Technical Product Managers Should Learn
A Technical Product Manager does not need to train the model, but they must understand how the model behaves inside the product.
They must know how to ask why the model is being released, who should receive it first, what risks need to be reduced, which metrics decide success, what happens if something goes wrong, how users will be protected, and how the team will know whether the new model is actually better.
This is the real work of AI product leadership.
It is not just about moving a model from staging to production. It is about protecting users while improving the product. It is about creating a rollout path where the team learns from reality without turning users into test subjects.
That is why safe AI rollout is not only an engineering process.
It is a product thinking skill.
Final Takeaway
To safely release a new AI model, a team should not move directly from offline testing to full launch.
That path is too risky.
A safer path starts with clarity. The team should understand the goal, scope, and constraints before choosing the rollout method. After that, offline evaluation should confirm that the model is promising. Shadow testing should expose the model to real traffic without showing its answers to users. Canary rollout should then test the model with a small live audience. A/B testing should measure real product impact. Finally, gradual ramp-up and continuous monitoring should protect users after launch.
This approach helps the team improve the product without damaging trust.
Because in AI products, the most important question is not only, “Is the model better?”
The deeper question is:
Can we safely release this model without hurting users, trust, speed, or business outcomes?
That is the mindset every Technical Product Manager needs.